
If you’ve been following AI developments over the past few years, you’ve probably heard about large language models (LLMs) like GPT-4 and Claude that can generate impressively human-like text. But there’s a new kid on the block that’s shaking up the AI world: diffusion-based large language models (dLLMs).
What Are Diffusion LLMs and Why Should You Care?
Inception Labs recently introduced diffusion-based large language models that are turning heads in the AI community. Why? Because they’re accomplishing something remarkable: generating text that’s just as good as the leading models but doing it 10 times faster and at 90% lower cost.
Think about that for a second. The same quality of AI text generation, but at a fraction of the time and cost. This isn’t just an incremental improvement—it’s a paradigm shift that could democratize access to powerful AI tools.
Breaking Down the Traditional LLM Approach
To understand why diffusion LLMs are so revolutionary, let’s first look at how traditional models like GPT-4 work:

Traditional autoregressive LLMs generate text one token (roughly one word or part of a word) at a time, in sequence. Imagine writing a sentence but only being allowed to see what you’ve already written, never looking ahead. Each new word depends entirely on the words that came before it.
This approach has some significant drawbacks:
- Speed limitations: The model must complete a full calculation cycle for each new token
- Error propagation: If the model makes a mistake early on, that error gets carried through the entire generation
- One-way thinking: The model can only reason in one direction (left to right)
It’s like driving with your eyes glued to the rearview mirror—you can see where you’ve been, but you’re driving blind when it comes to what’s ahead.
The Diffusion LLM Revolution: A New Way to Generate Text
Diffusion LLMs take a completely different approach, inspired by the technology that powers those AI image generators you’ve probably played with.
Instead of generating text token by token, diffusion LLMs:
- Start with random noise (think static on an old TV)
- Gradually refine the entire text segment through 5-10 “denoising” steps
- Process all output positions simultaneously during each step
This parallel processing approach is what enables the dramatic speed improvements. But the benefits go beyond just speed:
- Self-correction: The model can revise earlier parts of the text as it goes
- Bidirectional reasoning: It can “think” in both directions at once
- Massive parallelization: It’s like having thousands of writers working in perfect coordination
The Numbers Don’t Lie: Performance Comparison
Let’s look at how diffusion LLMs stack up against the current leading models:
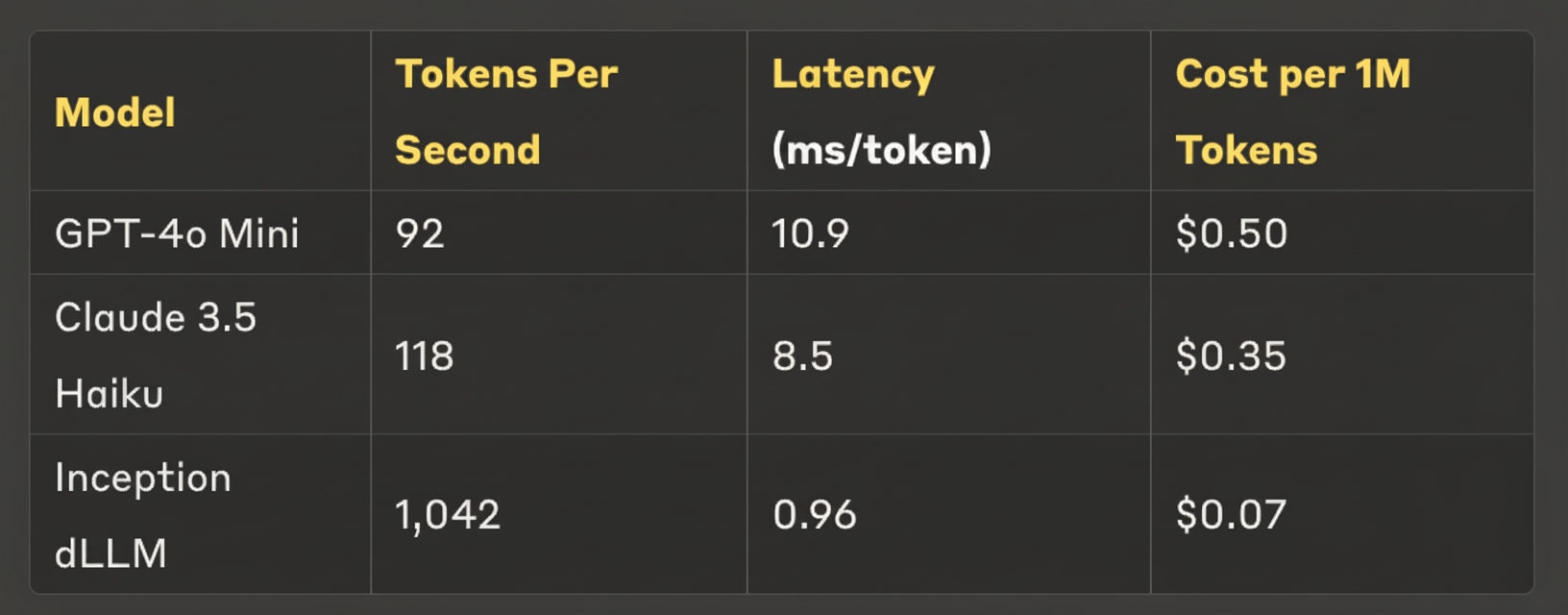
That’s not a typo—Inception’s diffusion LLM generates text at over 1,000 tokens per second. To put that in perspective, this entire blog post could be generated in under two seconds!
And the cost savings are just as impressive. At $0.07 per million tokens (compared to $0.50 for GPT-4o Mini), companies could potentially reduce their AI text generation costs by 86%.
Beyond Speed: Where Diffusion LLMs Excel
Speed and cost aren’t the only advantages. Diffusion LLMs show particular strengths in tasks that require bidirectional reasoning—thinking about the relationship between different parts of text in any order, not just left to right.
For example, in reversal poem completion tasks (where the meaning changes when read backward), diffusion LLMs achieve 87% accuracy compared to just 42% for traditional models.
They also show improvements in complex reasoning tasks. On the GSM8K math problem-solving benchmark, diffusion LLMs reached 82% accuracy versus 78% for comparable traditional models—likely because they can correct calculation mistakes mid-process rather than being stuck with early errors.
The Tech Behind the Magic
So how do diffusion LLMs actually work? Here are the key technical innovations:
Continuous Embedding Space
One of the challenges in adapting diffusion models to text is that text is made up of discrete tokens, while diffusion works best in continuous space (like image pixels). Inception Labs solved this by:
- Converting tokens to continuous embeddings using a technique called VQ-VAE
- Applying diffusion in this continuous space
- Converting back to discrete tokens at the end
Hybrid Architecture
Diffusion LLMs use a combination of:
- Transformer layers: To handle semantic relationships between words
- U-Net components: To manage the iterative refinement process
This hybrid approach blends the best of both worlds—the linguistic understanding of transformers with the refinement capabilities of U-Nets.
Advanced Training Methods
The training process combines several innovative approaches:
- Noise Schedule Curriculum: Gradually increasing noise levels during training
- Multi-Task Optimization: Training for both denoising accuracy and output quality
- Adversarial Regularization: Using discriminator networks to ensure outputs match natural language patterns
Real-World Applications: Where Diffusion LLMs Shine
The speed and efficiency advantages of diffusion LLMs open up exciting new possibilities:
Edge Computing
With traditional LLMs, running sophisticated AI on your smartphone or laptop has been a pipe dream. But diffusion LLMs are changing that—Mercury Coder (an implementation from Inception Labs) can generate 45 tokens per second on an iPhone 16 Pro.
Small but Mighty: Working Within the Limitations of Large Language Models
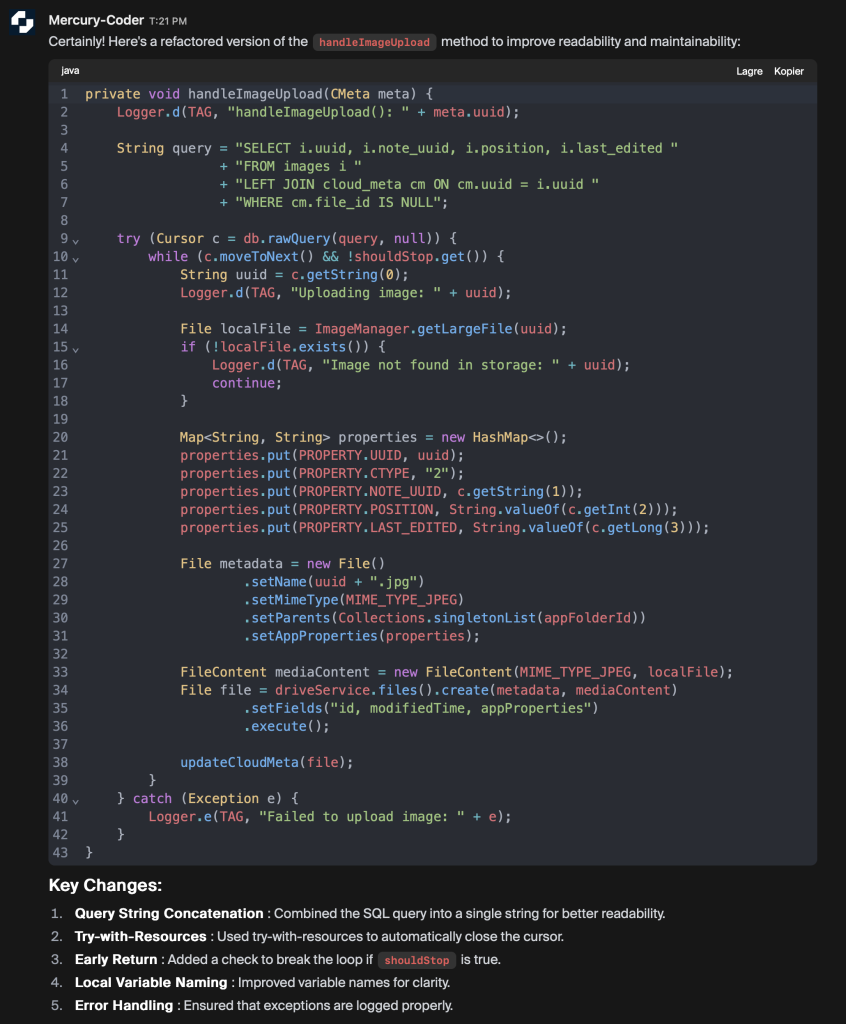
Above is an example of refactoring some Java code I made using Inception’s Mercury-Coder. The code fetches some data from SQLite database and uses this to upload a file to Google Drive.
In my recent exploration of deep learning language models (dLLMs), I’ve encountered some interesting practical limitations worth sharing. These powerful AI tools promise to revolutionize coding workflows, but they come with constraints that shape how we can use them effectively.
When I attempted to refactor a substantial codebase by pasting 1,000 lines of code, I hit a wall. The model simply couldn’t process that volume of text due to its input limitations. Undeterred, I scaled back to about 200 lines, but even that exceeded the threshold.
Success finally came when I narrowed my focus to a single function of approximately 50 lines. While this might seem restrictive, it opened up a practical testing ground. By working with these bite-sized chunks of code, I could still evaluate the model’s ability to understand, refactor, and improve my code.
This experience highlighted an important approach to working with current AI coding assistants: breaking problems down into manageable pieces. Rather than viewing this as a limitation, I’ve come to see it as an opportunity to be more deliberate about code review and refactoring. The constraint forces me to isolate specific functions or modules, which often leads to more focused improvements.
For those exploring these tools in their own workflows, I recommend:
- Identifying smaller, self-contained functions for refactoring
- Breaking larger problems into component parts
- Using the AI to review code section by section
While I’m looking forward to future improvements that may expand these boundaries, I’ve found value in working within the current constraints. Sometimes limitations don’t restrict creativity—they channel it.
Imagine having GPT-4 level capabilities right on your phone, without needing an internet connection or sending your data to the cloud.
Real-Time Applications
The reduced latency makes diffusion LLMs perfect for applications where speed matters:
- Live translation during conversations
- Real-time coding assistants that complete your code as you type
- Interactive AI systems that respond instantly
Democratized Access
Perhaps most importantly, the drastically reduced costs could make powerful AI text generation accessible to smaller companies, educational institutions, and developers who couldn’t previously afford it.
Current Limitations
Diffusion LLMs aren’t perfect (yet). Here are some of their current limitations:
- Context Window: Current models support 4K token contexts versus 128K in frontier autoregressive models
- Long-Form Coherence: When generating very long text (>10K tokens), there can be slight coherence issues
- Tooling Integration: Existing LLM tools need to be adapted for diffusion-specific APIs
What’s Next for Diffusion LLMs?
Industry analysts predict rapid evolution in three key areas:
- Hybrid Architectures: Combining autoregressive planning with diffusion refinement
- Multimodal Expansion: Unified frameworks for generating text, images, and video together
- Specialized Hardware: New chips optimized specifically for parallel denoising operations
The Bottom Line
Diffusion-based LLMs represent the first major architectural innovation in language models since the transformer architecture that powers models like GPT and Claude. We’re moving from “single-threaded reasoning” to “parallelized, corrective generation”—and the implications are enormous.
While traditional LLMs still have advantages in some scenarios (particularly those requiring extremely long contexts), diffusion LLMs’ dramatic speed improvements and cost reductions make them superior for many real-world applications.
As the CEO of Inception Labs put it: “This represents the first major architectural innovation in language models since the transformer—we’re moving from single-threaded reasoning to parallelized, corrective generation.”
The AI text generation landscape is changing rapidly, and diffusion LLMs are leading the charge. Whether you’re a developer, business leader, or just someone interested in AI, this is a technology worth watching closely. The future of AI text generation isn’t just faster—it’s fundamentally different.